

 4 932
4 932
 Что такое? Pandas – это программная библиотека, написанная на Python. Ее задачи – сбор, первичная оценка сведений и их статистический учет. В целом создана для облегчения работы с большими объемами данных.
Что такое? Pandas – это программная библиотека, написанная на Python. Ее задачи – сбор, первичная оценка сведений и их статистический учет. В целом создана для облегчения работы с большими объемами данных.
 Каковы преимущества? Хорошие показатели скорости, интуитивно понятный интерфейс, интеграция с другими библиотеками для расширения функционала – все это делает Pandas одной из лучших программ для работы с данными.
Каковы преимущества? Хорошие показатели скорости, интуитивно понятный интерфейс, интеграция с другими библиотеками для расширения функционала – все это делает Pandas одной из лучших программ для работы с данными.
В статье рассказывается:
- Что собой представляет библиотека Рandas
- Для чего нужна библиотека Рandas
- Ключевые возможности
- Преимущества Pandas
- Пошаговая установка Pandas
- Класс Series
- Data Frame
- Как считывать данные в DataFramepandas
-
 Пройди тест и узнай, какая сфера тебе подходит:
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Что собой представляет библиотека Рandas
Название библиотеки образовано сочетанием двух слов – PANel DAta. Она используется для анализа структурированных данных, размещенных в таблицах (панелях). Рandas упрощает анализ информации, тестирование приложений и другие действия, предоставляя разработчику готовые алгоритмы.
Инструмент базируется на языке Python и применяется для предварительного преобразования, обработки и очистки структурированных данных, представленных в форматах, не подходящих для машинного обучения, например, в виде таблиц Excel.
Основные направления использования Pandas Python:
- Группировка данных по заданным параметрам.
- Объединение нескольких таблиц в одну сводную.
- Очищение данных от дубликатов и невалидных строк или столбцов.
- Вывод определенных значений по фильтрам или уникальности.
- Использование агрегирующих функций, включая подсчет значений, суммы элементов, определение среднего значения.
- Визуализация собранных данных.
Рandas – один из многочисленных инструментов для анализа данных, обращение с которыми входит в программу обучения по специальности «Аналитик данных».
Библиотека Рandas не входит в число встроенных функций Python. Она устанавливается по инструкции, размещенной на официальном сайте. Для начала стоит установить программу Anaconda для управления пакетами для работы данными, содержащую Pandas. После скачивания функции, доступные в этой библиотеки, используются при написании кода на Python.

Для работы с данными, как правило, применяют Jupyter Notebook. Это специальная среда разработки, подходящая для кодирования на Python с использованием возможностей библиотеки Рandas, а также для итерационного выполнения программ и анализа результатов выполнения отдельных операций, в том числе выборки из таблиц
Для чего нужна библиотека Рandas
Сфера применения Рandas настолько широка, что проще перечислить функции, с которыми она не справится.
Библиотека представляет собой комфортное место, в котором вы можете проделывать с вашими данными любые действия: собирать, очищать, преобразовывать и анализировать.
входят в ТОП-30 с доходом
от 210 000 ₽/мес

Скачивайте и используйте уже сегодня:


Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда

Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Предположим, что вам необходимо изучить набор данных с вашего компьютера в формате CSV. С помощью Pandas информация будет извлечена из CSV в DataFrame, то есть представлена в виде таблицы, а затем вы сможете:
- Рассчитать статистику и получить ответы на следующие вопросы:
- Каково среднее значение, медиана, максимум или минимум для каждого столбца?
- Коррелирует ли столбец A со столбцом B?
- Как выглядит распределение данных в столбце C?
- Провести очистку данных, в том числе удалить пропущенные значения или отфильтровать строки или столбцы по заданным критериям.
- Визуализировать данные с помощью Matplotlib, построив столбчатые диаграммы, линейные графики или гистограммы.
- Сохранить очищенные и преобразованные данные в CSV и другие форматы файлов или в базе данных.
Рandas – лучший инструмент, позволяющий разобраться в природе вашего набора данных. После этого их моделирование или сложная визуализация не составит труда.
Ключевые возможности
Набор функций библиотеки Рandas весьма обширен. Разработчики ценят этот продукт за следующие компоненты, упрощающие анализ данных и другие действия с ними:
- объекты data frame, позволяющие управлять индексированными массивами двумерной информации;
- встроенные инструменты совмещения данных, а также обработки сопутствующих сведений;
- функция обмена электронными материалами между структурами памяти, а также различными файлами и документами;
- срезы по значениям индексов;
- расширенные возможности при индексировании;
- наличие выборки из больших объемов наборов информации;
- вставка и удаление столбцов в массиве;
- встроенные средства совмещения информации;
- обработка отсутствующих сведений;
- слияние имеющихся информационных наборов;
- иерархическое индексирование, помогающее обрабатывать материалы высокой размерности в структурах с меньшей размерностью;
- группировка, делающая доступными одновременные трехэтапные операции типа «разделение, изменение и объединение».
Читайте также!

Полезными функциями библиотеки Pandas являются поддержка временных рядов, формирование периодов, изменение интервалов. Как и другие возможности, они предназначены для повышения производительности при работе с данными.
Преимущества Pandas
- Высокая скорость благодаря оптимизации кода.
- Интуитивно понятный интерфейс.
- Расширенные возможности за счет интеграции с другим библиотеками на Python, в частности, с NumPy, Matplotlib и Scikit-learn.
- Сильное мировое комьюнити, силами которого продукт постоянно совершенствуется.
Пошаговая установка Pandas
Шаг 1. Самый простой способ приступить к работе с библиотекой описан на официальном сайте продукта. В первую очередь устанавливается размещенный на этом же ресурсе дистрибутив для Python с набором библиотек – Anaconda.

Новичкам помогут успешно справиться с этой задачей несколько советов:
- Становитесь на рекомендованных настройках, например, Install for: Just me (recommended). Изменения можно вносить по мере освоения программы.
- Запуск по умолчанию активируется галочкой «Add Anaconda to my PATH environment variable», иначе каждый раз придется включать Anaconda вручную.
- Вопрос: «Do you wish to initialize Anaconda3?» (Хотите ли вы инициализировать Anaconda3?) предполагает ответ «Да».
Завершив установку программы, перезагрузите компьютер.
Скачать файлШаг 2. В командной строке Anaconda напишите JupyterLab: так вы запустите интерактивную среду для работы с кодом, данными и блокнотами, входящую в пакет дистрибутива.
Шаг 3. В JupyterLab необходимо создать новый блокнот Python3.
Шаг 4. В первой ячейке пропишите: import pandas as pd, после этого можно приступать к написанию кода в следующих ячейках.
Класс Series
Series – объект, по виду напоминающий одномерный массив. В него могут входить любые типы данных. Как правило, представляет собой столбец таблицы с последовательностями тех или иных значений, каждое из которых наделено индексом – номером строки.

Обработка соответствующего кода завершается появлением на экране такой записи:

Series выглядит как таблица с индексами компонентов. В первом столбце выводится соответствующая информация, во второй размещаются заданные значения.
Data Frame
DataFrame – основной тип информации в Pandas. Это двумерная информационная структура в виде таблицы с разными типами столбцов. Вся дальнейшая работа ведется на основе DataFrame.
Объект данных может выглядеть как обычная таблица, например, в Excel, и включать любое количество столбцов и строк. Содержимое ячеек представляет сведения разных типов:
- числовые;
- булевы;
- строковые и так далее.
В DataFrame индексы присваиваются не только столбцам, но и строкам. Такая особенность позволяет сортировать и фильтровать данные, а также ускоряет и упрощает процесс поиска нужных значений.
В DataFrame поддерживается жесткое кодирование, а также импорт:
- CSV.
- TSV.
- Excel-документов.
- SQL-таблиц.
Соответствующий компонент может создаваться при помощи команды:

Где:
- data – это создание объекта из входных сведений (NumPy, series, dict и аналогичные им);
- index – строковые метки;
- columns – создание подписей столбцов;
- dtype – ссылка на тип сведений, содержащихся в каждом столбце (факультативный параметр);
- copy – копирование сведений, если они предусмотрены изначально.
 ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
Создавать DataFrame можно по-разному, например, формируя объект из словаря или списков, кортежей, файла Excel.
Так выглядит код для создания DataFrame на базе списка словарей:
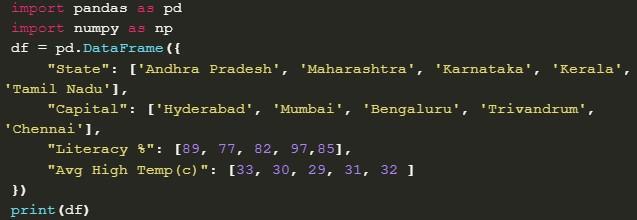
Обработка предложенного фрагмента завершится выводом на экран устройства следующей информации:
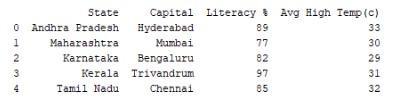
Принцип работы кода достаточно прост: после создания словаря в него передается метод DataFrame() в качестве аргумента. Получив те или иные значения, система выводит объект на печать.
Индекс с метками строк отображается в крайнем левом столбце. Сама таблица – это заголовки и электронные материалы. Используя настройки индексных параметров, возможно создать индексированные DataFrames.
Как считывать данные в DataFrame pandas
Процесс загрузки данных в DataFrame из файлов различных форматов несложен.
Чтение данных из CSV-файлов
Чтобы загрузить данные из файлов CSV, прописывается строка:
df = pd.read_csv(‘purchases.csv’)
df
У CSV нет индексов, как у DataFrames, поэтому достаточно определить index_col при чтении:
df = pd.read_csv(‘purchases.csv’, index_col=0)
df
Так мы устанавливаем, что индексом будет нулевой столбец.
У большинства CSV индексного столбца нет, поэтому этот шаг вас не должен волновать.
Чтение данных из JSON
Файл JSON представляет собой хранимый словарь Python, а значит, для pandas не составит труда прочитать его:
df = pd.read_json(‘purchases.json’)
df
Использование JSON делает возможной работу через вложенность, поэтому на этот раз нами получен правильный индекс. Чтобы посмотреть, как работает файл data_file.json, откройте его в блокноте.
Чтение данных из базы данных SQL
При работе с базой данных SQL для начала используйте соответствующую библиотеку Python для установки соединения и последующей передачи запроса в Pandas. Продемонстрируем этот процесс с использованием SQLite.

В первую очередь устанавливаем pysqlite3. Выполняем в терминале следующую команду:
pip install pysqlite3
Если вы в Jupyter Notebook, запускаете эту ячейку:
!pip install pysqlite3
sqlite3 нужен, чтобы соединиться с базой данных, которая впоследствии будет использоваться для создания DataFrame с помощью запроса SELECT.
Создаем соединение с файлом базы данных SQLite:
import sqlite3
con = sqlite3.connect(«database.db»)





Если вы применяете для хранения данных PostgreSQL, MySQL или другой SQL-сервер, для установки соединения вам надо использовать правильную библиотеку Python. Можно соединяться не с файлом, как в нашем примере с SQLite, а с URI базы данных.
В этой базе данных SQLite у нас есть таблица под названием purchases, а наш индекс — столбец index.
После передачи запроса SELECT и нашего con, мы можем читать из таблицы purchases:
df = pd.read_sql_query(«SELECT * FROM purchases», con)
df
Как и в случае с CSV, можно передать index_col=’index’ или установить индекс постфактум:
df = df.set_index(‘index’)
df
Читайте также!

Использование set_index() возможно в любое время и для любого DataFrame с применением любого столбца. Поскольку задачу по индексированию Series и DataFrame приходится решать часто, вам пригодится знание различных способов.
По сути, Pandas можно назвать более мощным аналогом Excel. Эта библиотека позволяет программисту оперировать большими объемами данных, где количество строк измеряется тысячами, а иногда и миллионами. Инструменты анализа, содержащиеся в Pandas, обеспечивают высокую производительность работы с данными.


 0
0 











 Разберем 11 самых важных жизненных вопросов
Разберем 11 самых важных жизненных вопросов






