

 139 555
139 555 В статье рассказывается:
- Готовим поляну
- Библиотека pyttsx3
- Как озвучить системное время в Windows и Linux
- Обертка для eSpeak NG
- Управляем речью через Speech Dispatcher в Linux
- Модуль Google TTS — голоса из интернета
- Выводим текст через NVDA
- Заключение
-
 Пройди тест и узнай, какая сфера тебе подходит:
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Синтез речи может пригодиться вам в работе над мобильным помощником, умным домом на Raspberry Pi, искусственным интеллектом, игрой, системой уведомлений и звуковым интерфейсом. Голосовые сообщения донесут информацию до пользователя, которому некогда читать текст. Кроме того, если программа умеет озвучивать свой интерфейс, она доступна незрячим и слабовидящим. Есть системы управления компьютером без опоры на зрение. Одна из самых популярных — NVDA (NonVisual Desktop Access) — написана на Python с добавлением C++.

Давайте посмотрим, как использовать text-to-speech (TTS) в Python и подключать синтезаторы голоса к вашей программе. Эту статью я хотела назвать «Говорящая консоль», потому что мы будем писать консольное приложение для Windows, Linux, а потенциально — и MacOS. Потом решила выбрать более общее название, ведь от наличия GUI суть не меняется. На всякий случай поясню: консоль в данном случае — терминал Linux или знакомая пользователям Windows командная строка.
входят в ТОП-30 с доходом
от 210 000 ₽/мес

Скачивайте и используйте уже сегодня:


Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда

Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Цель выберем очень скромную: создадим приложение, которое будет каждую минуту озвучивать текущее системное время.
Готовим поляну
Прежде чем писать и тестировать код, убедимся, что операционная система готова к синтезу речи, в том числе на русском языке.
Чтобы компьютер заговорил, нужны:
- голосовой движок (синтезатор речи) с поддержкой нужных нам языков,
- голоса дикторов для этого движка.
В Windows есть штатный речевой интерфейс Microsoft Speech API (SAPI). Голоса к нему выпускают, помимо Microsoft, сторонние производители: Nuance Communications, Loquendo, Acapela Group, IVONA Software.
Есть и свободные кроссплатформенные голосовые движки:
- RHVoice от Ольги Яковлевой — имеет четыре голоса для русского языка (один мужской и три женских), а также поддерживает татарский, украинский, грузинский, киргизский, эсперанто и английский. Работает в Windows, GNU/Linux и Android.
- eSpeak и его ответвление — eSpeak NG — c поддержкой более 100 языков и диалектов, включая даже латынь. NG означает New Generation — «новое поколение». Эта версия разрабатывается сообществом с тех пор, как автор оригинальной eSpeak перестал выходить на связь. Система озвучит ваш текст в Windows, Android, Linux, Mac, BSD. При этом старый eSpeak стабилен в ОС Windows 7 и XP, а eSpeak NG совместим с Windows 8 и 10.

В статье я ориентируюсь только на перечисленные свободные синтезаторы, чтобы мы могли писать кроссплатформенный код и не были привязаны к проприетарному софту.
По качеству голоса RHVoice неплох и к нему быстро привыкаешь, а вот eSpeak очень специфичен и с акцентом. Зато eSpeak запускается на любом утюге и подходит как вариант на крайний случай, когда ничто другое не работает или не установлено у пользователя.
Установка речевых движков, голосов и модулей в Windows
С установкой синтезаторов в Windows проблем возникнуть не должно. Единственный нюанс — для русского голоса eSpeak и eSpeak NG нужно скачать расширенный словарь произношения. Распакуйте архив в подкаталог espeak-data или espeak-ng-data в директории программы. Теперь замените старый словарь новым: переименуйте ru_dict-48 в ru_dict, предварительно удалив имеющийся файл с тем же именем (ru_dict).
Скачать файлТеперь установите модули pywin32, python-espeak и py-espeak-ng, которые потребуются нам для доступа к возможностям TTS:
pip install pywin32 python-espeak pyttsx3 py-espeak-ng
Если у вас на компьютере соседствуют Python 2 и 3, здесь и далее пишите «pip3», а при запуске скриптов — «python3».
Установка eSpeak(NG) в Linux
Подружить «пингвина» с eSpeak, в том числе NG, можно за минуту:
sudo apt-get install espeak-ng python-espeak
pip3 install py-espeak-ng pyttsx3
Дальше загружаем и распаковываем словарь ru_dict с официального сайта:
wget http://espeak.sourceforge.net/data/ru_dict-48.zip
unzip ru_dict-48.zip
Теперь ищем адрес каталога espeak-data (или espeak-ng-data) где-то в /usr/lib/ и перемещаем словарь туда. В моем случае команда на перемещение выглядела так:
sudo mv ru_dict-48 /usr/lib/i386-linux-gnu/espeak-data/ru_dict
Обратите внимание: вместо «i386» у вас в системе может быть «x86_64…» или еще что-то. Если не уверены, воспользуйтесь поиском:
find /usr/lib/ -name «espeak-data»
Готово!
RHVoice в Linux
Инструкцию по установке RHVoice в Linux вы найдете, например, в начале этой статьи. Ничего сложного, но времени занимает больше, потому что придется загрузить несколько сотен мегабайт.
на обучение «Python-разработчик» до 14 июня
Смысл в том, что мы клонируем git-репозиторий и собираем необходимые компоненты через scons.
Для экспериментов в Windows и Linux я использую одни и те же русские голоса: стандартный ‘ru’ в eSpeak и Aleksandr в RHVoice.

Как проверить работоспособность синтезатора
Прежде чем обращаться к движку, убедитесь, что он установлен и работает правильно.
Проверить работу eSpeak в Windows проще всего через GUI — достаточно запустить TTSApp.exe в папке с программой. Дальше открываем список голосов, выбираем eSpeak-RU, вводим текст в поле редактирования и жмем на кнопку Speak.
Обратиться к espeak можно и из терминала. Базовые консольные команды для eSpeak и NG совпадают — надо только добавлять или убирать «-ng» после «espeak»:
espeak -v ru -f D:\my.txt
espeak-ng -v en «The Cranes are Flying»
echo «Да, это от души. Замечательно. Достойно восхищения» |RHVoice-test -p Aleksandr
Как нетрудно догадаться, первая команда с ключом -f читает русский текст из файла. Чтобы в Windows команда espeak подхватывалась вне зависимости от того, в какой вы директории, добавьте путь к консольной версии eSpeak (по умолчанию — C:\Program Files\eSpeak\command_line) в переменную окружения Path. Вот как это сделать.
Библиотека pyttsx3
PyTTSx3 — удобная кроссплатформенная библиотека для реализации TTS в приложениях на Python 3. Использует разные системы синтеза речи в зависимости от текущей ОС:
- в Windows — SAPI5,
- в Mac OS X — nsss,
- в Linux и на других платформах — eSpeak.
Это очень удобно: пишете код один раз и он работает везде. Кстати, eSpeak NG поддерживается наравне с исходной версией.
А теперь примеры!
Просмотр голосов
У каждого голоса есть несколько параметров, с которыми можно работать:
- id (идентификатор в операционной системе),
- name (имя),
- languages (поддерживаемые языки),
- gender (пол),
- age (возраст).
Первый вопрос всегда в том, какие голоса установлены на стороне пользователя. Поэтому создадим скрипт, который покажет все доступные голоса, их имена и ID. Назовем файл, например, list_voices.py:
import pyttsx3
tts = pyttsx3.init() # Инициализировать голосовой движок.
У активного движка есть стандартный параметр ‘voices’, где содержится список всех доступных этому движку голосов. Это нам и нужно:
voices = tts.getProperty(‘voices’)
# Перебрать голоса и вывести параметры каждого
for voice in voices:
print(‘=======’)
print(‘Имя: %s’ % voice.name)
print(‘ID: %s’ % voice.id)
print(‘Язык(и): %s’ % voice.languages)
print(‘Пол: %s’ % voice.gender)
print(‘Возраст: %s’ % voice.age)
Теперь открываем терминал или командную строку, переходим в директорию, куда сохранили скрипт, и запускаем list_voices.py.
Результат будет примерно таким:
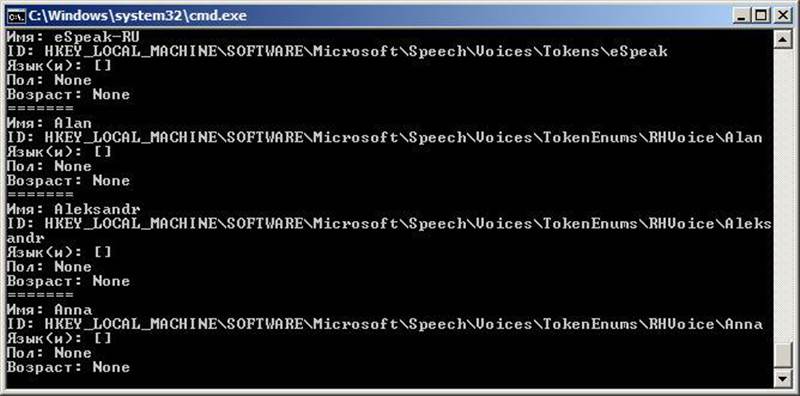
В Linux картина будет похожей, но с другими идентификаторами.
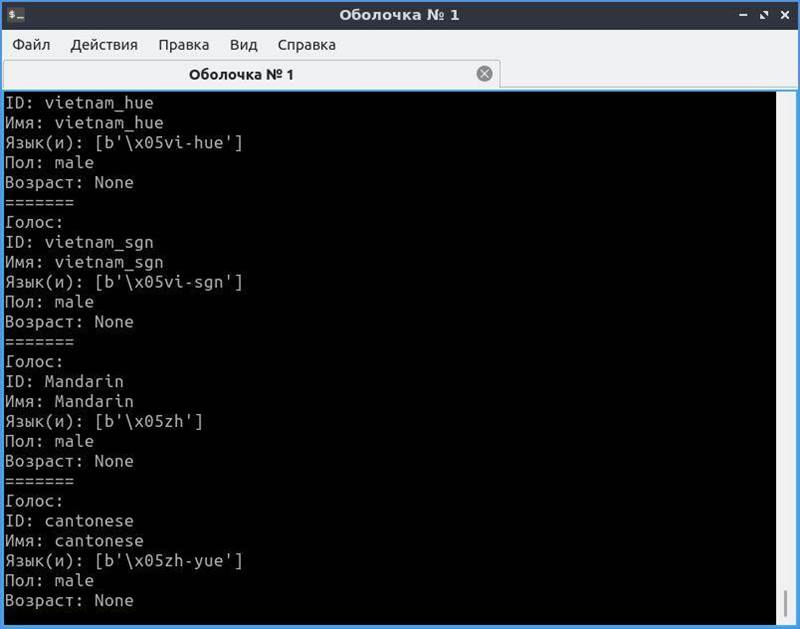
Как видите, в Windows для большинства установленных голосов MS SAPI заполнены только «Имя» и ID. Однако этого хватит, чтобы решить следующую нашу задачу: написать код, который выберет русский голос и что-то им произнесет.
 ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
Например, у голоса RHVoice Aleksandr есть преимущество — его имя уникально, потому что записано транслитом и в таком виде не встречается у других известных производителей голосов. Но через pyttsx3 этот голос будет работать только в Windows. Для воспроизведения в Linux ему нужен Speech Dispatcher (подробнее чуть позже), с которым библиотека взаимодействовать не умеет. Как общаться с «диспетчером» еще обсудим, а пока разберемся с доступными голосами.
Как выбрать голос по имени
В Windows голос удобно выбирать как по ID, так и по имени. В Linux проще работать с именем или языком голоса. Создадим новый файл set_voice_and_say.py:
import pyttsx3
tts = pyttsx3.init()
voices = tts.getProperty(‘voices’)
# Задать голос по умолчанию
tts.setProperty(‘voice’, ‘ru’)
# Попробовать установить предпочтительный голос
for voice in voices:
if voice.name == ‘Aleksandr’:
tts.setProperty(‘voice’, voice.id)
tts.say(‘Командный голос вырабатываю, товарищ генерал-полковник!’)
tts.runAndWait()
В Windows вы услышите голос Aleksandr, а в Linux — стандартный русский eSpeak. Если бы мы вовсе не указали голос, после запуска нас ждала бы тишина, так как по умолчанию синтезатор говорит по-английски.
Обратите внимание: tts.say() не выводит реплики мгновенно, а собирает их в очередь, которую затем нужно запустить на воспроизведение командой tts.runAndWait().
Выбор голоса по ID
Часто бывает, что в системе установлены голоса с одинаковыми именами, поэтому надежнее искать необходимый голос по ID.
Заменим часть написанного выше кода:
for voice in voices:
ru = voice.id.find(‘RHVoice\Anna’) # Найти Анну от RHVoice
if ru > -1: # Eсли нашли, выбираем этот голос
tts.setProperty(‘voice’, voice.id)
Теперь в Windows мы точно не перепутаем голоса Anna от Microsoft и RHVoice. Благодаря поиску в подстроке нам даже не пришлось вводить полный ID голоса.
Но когда мы пишем под конкретную машину, для экономии ресурсов можно прописать голос константой. Выше мы запускали скрипт list_voices.py — он показал параметры каждого голоса в ОС. Тогда-то вы и могли обратить внимание, что в Windows идентификатором служит адрес записи в системном реестре:
import pyttsx3
tts = pyttsx3.init()
EN_VOICE_ID = «HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\MS-Anna-1033-20DSK»
RU_VOICE_ID = «HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\TokenEnums\RHVoice\Anna»
# Использовать английский голос
tts.setProperty(‘voice’, EN_VOICE_ID)
tts.say(«Can you hear me say it’s a lovely day?»)
# Теперь — русский
tts.setProperty(‘voice’, RU_VOICE_ID)
tts.say(«А напоследок я скажу»)
tts.runAndWait()
Как озвучить системное время в Windows и Linux

Это крошечное приложение каждую минуту проговаривает текущее время по системным часам. Точнее, оно сообщает время при каждой смене минуты. Например, если вы запустите скрипт в 14:59:59, программа заговорит через секунду.
Создадим новый файл с именем time_tts.py. Всего, что мы разобрали выше, должно хватить, чтобы вы без проблем прочли и поняли следующий код:
# «Говорящие часы» — программа озвучивает системное время
from datetime import datetime, date, time
import pyttsx3, time
tts = pyttsx3.init()
tts.setProperty(‘voice’, ‘ru’) # Наш голос по умолчанию
tts.setProperty(‘rate’, 150) # Скорость в % (может быть > 100)
tts.setProperty(‘volume’, 0.8) # Громкость (значение от 0 до 1)
def set_voice(): # Найти и выбрать нужный голос по имени
voices = tts.getProperty(‘voices’)
for voice in voices:
if voice.name == ‘Aleksandr’:
tts.setProperty(‘voice’, voice.id)
else:
pass
def say_time(msg): # Функция, которая будет называть время в заданном формате
set_voice() # Настроить голос
tts.say(msg)
tts.runAndWait() # Воспроизвести очередь реплик и дождаться окончания речи
while True:
time_checker = datetime.now() # Получаем текущее время с помощью datetime
if time_checker.second == 0:
say_time(‘{h} {m}’.format(h=time_checker.hour, m=time_checker.minute))
time.sleep(55)
else:
pass
Программа будет отслеживать и называть время, пока вы не остановите ее сочетанием клавиш Ctrl+Break или Ctrl+C (в Windows и Linux соответственно).
Для дальнейшего изучения библиотеки pyttsx3 вы можете заглянуть в англоязычную документацию, в том числе справку по классу и примеры. А пока посмотрим на другие инструменты.
Обертка для eSpeak NG
Модуль называется py-espeak-ng. Это альтернатива pyttsx3 для случаев, когда вам нужен или доступен только один синтезатор — eSpeak NG. Не дай бог, конечно. Впрочем, для быстрых экспериментов с голосом очень даже подходит. Принцип использования покажется вам знакомым:
from espeakng import ESpeakNG
engine = ESpeakNG()
engine.speed = 150
engine.say(«I’d like to be under the sea. In an octopus’s garden, in the shade!», sync=True)
engine.speed = 95
engine.pitch = 32
engine.voice = ‘russian’
engine.say(‘А теперь Горбатый!’, sync=True)
Обратите внимание на параметр синхронизации реплик sync=True. Без него синтезатор начнет читать все фразы одновременно — вперемешку. В отличие от pyttsx3, обертка espeakng не использует команду runAndWait(), и пропуск параметра sync сбивает очередь чтения.
Озвучиваем текст из файла
Не будем довольствоваться текстами в коде программы — пора научиться брать их извне. Тем более, это очень просто. В папке, где хранится только что рассмотренный нами скрипт, создайте файл test.txt с текстом на русском языке и в кодировке UTF-8. Теперь добавьте в конец кода такой блок:
text_file = open(«test.txt», «r»)
data = text_file.read()
tts.say(data, sync=True)
text_file.close()
Открываем файл на чтение, передаем содержимое в переменную data, затем воспроизводим голосом все, что в ней оказалось, и закрываем файл.
Управляем речью через Speech Dispatcher в Linux
До сих пор по результатам работы нашего кода в Linux выводился один суровый eSpeak. Пришло время позаботиться о друзьях Tux’а и порадовать их сравнительно реалистичными голосами RHVoice. Для этого нам понадобится Speech Dispatcher — аналог MS SAPI. Он позволяет управлять всеми установленными в системе голосовыми движками и вызывать любой из них по необходимости.
Скорее всего Speech Dispatcher есть у вас в системе по умолчанию. Чтобы обращаться к нему из кода Python, надо установить модуль speechd:
sudo apt install python3-speechd
Пробуем выбрать синтезатор RHVoice с помощью «диспетчера» и прочесть текст:
import speechd
tts_d = speechd.SSIPClient(‘test’)
tts_d.set_output_module(‘rhvoice’)
tts_d.set_language(‘ru’)
tts_d.set_rate(50)
tts_d.set_punctuation(speechd.PunctuationMode.SOME)
tts_d.speak(‘И нежный вкус родимой речи так чисто губы холодит’)
tts_d.close()
Получается, чтобы сделать кроссплатформенное приложение с поддержкой синтезатора RHVoice, нужно совместить pyttsx3 и speechd: проверить, в какой системе работает наш код, и выбрать SAPI или Speech Dispatcher. А в любой непонятной ситуации — откатиться на неказистый, но вездеходный eSpeak.
Однако для этого программа должна знать, где работает. Определить текущую ОС и ее разрядность очень легко! Лично я предпочитаю использовать для этого стандартный модуль platform, который не нужно устанавливать:
import platform
system = platform.system() # Вернет тип системы.
bit = platform.architecture() # Вернет кортеж, где разрядность — нулевой элемент
print(system)
print(bit[0])
Пример результата:
Windows
64bit
Кстати, не обязательно решать все за пользователя. На базе pyttsx3 вы при желании создадите меню выбора голоса с возможностью управлять такими параметрами, как высота голоса, громкость и скорость речи.
Модуль Google TTS — голоса из интернета

Google предлагает онлайн-озвучку текста с записью результата в mp3-файл. Это не для каждой задачи:
- постоянно нужен быстрый интернет;
- нельзя воспроизвести аудио средствами самого gtts;
- скорость обработки текста ниже, чем у офлайн-синтезаторов.
Что касается голосов, английский и французский звучат очень реалистично. Русский голос Гугла — девушка, которая немного картавит и вдобавок произносит «ц» как «ч». По этой причине ей лучше не доверять чтение аудиокниг, имен и топонимов.
Еще один нюанс. Когда будете экспериментировать с кодом, не называйте файл «gtts.py» — он не будет работать! Выберите любое другое имя, например use_gtts.py.
Простейший код, который сохраняет текст на русском в аудиофайл:
from gtts import gTTS
tts = gTTS(‘Иван Федорович Крузенштерн. Человек и пароход!’, lang=’ru’)
tts.save(‘tts_output.mp3’)
После запуска этого кода в директории, где лежит скрипт, появится запись. Чтобы воспроизвести файл «не отходя от кассы», придется использовать еще какой-то модуль или фреймворк. Годится pygame или pyglet.
Вот листинг приложения, которое построчно читает txt-файлы с помощью связки gtts и PyGame. Я заметила, что для нормальной работы этого скрипта текст из text.txt должен быть в кодировке Windows-1251 (ANSI).
Выводим текст через NVDA

Мы научились озвучивать приложение с помощью установленных в системе синтезаторов. Но что если большинству пользователей эта фишка не нужна, и мы хотим добавить речь исключительно как опцию для слабовидящих? В таком случае не обязательно писать код озвучивания: достаточно передать текст интерфейса другому приложению — экранному диктору.
Одна из самых популярных программ экранного доступа в Windows — бесплатная и открытая NVDA. Для связи с ней к нашему приложению нужно привязать библиотеку nvdaControllerClient (есть варианты для 32- и 64-разрядных систем). Узнавать разрядность системы вы уже умеете.
Еще для работы с экранным диктором нам понадобятся модули ctypes и time. Создадим файл nvda.py, где напишем модуль связи с NVDA:
import time, ctypes, platform
# Загружаем библиотеку клиента NVDA
bit = platform.architecture()
if bit[0] == ’32bit’:
clientLib = ctypes.windll.LoadLibrary(‘nvdaControllerClient32.dll’)
elif bit[0] == ’64bit’:
clientLib = ctypes.windll.LoadLibrary(‘nvdaControllerClient64.dll’)
else:
errorMessage=str(ctypes.WinError(res))
ctypes.windll.user32.MessageBoxW(0,u»Ошибка! Не удалось определить разрядность системы!»,0)
# Проверяем, запущен ли NVDA
res = clientLib.nvdaController_testIfRunning()
if res != 0:
errorMessage=str(ctypes.WinError(res))
ctypes.windll.user32.MessageBoxW(0,u»Ошибка: %s»%errorMessage,u»нет доступа к NVDA»,0)
def say(msg):
clientLib.nvdaController_speakText(msg)
time.sleep(1.0)
def close_speech():
clientLib.nvdaController_cancelSpeech()
Теперь эту заготовку можно применить в коде основной программы:
import nvda
nvda.say(‘Начать игру’)
# … другие реплики или сон
nvda.close_speech()
Если NVDA неактивна, после запуска кода мы увидим окошко с сообщением об ошибке, а если работает — услышим от нее заданный текст.
Плюс подхода в том, что незрячий пользователь будет слышать тот голос, который сам выбрал и настроил в NVDA.
Заключение
Ваша программа уже глаголет устами хотя бы одного из установленных синтезаторов? Поздравляю! Как видите, это не слишком сложно и «в выигрыше даже начинающий». Еще больше радуют перспективы использования TTS в ваших проектах. Все, что можно вывести как текст, можно и озвучить.
Представьте утилиту, которая при внезапной проблеме с экраном телефона или монитора сориентирует пользователя по речевым подсказкам, поможет спокойно сохранить данные и штатно завершить работу. Или как насчет прослушивания входящей почты, когда вы не за монитором? Напишите, когда, на ваш взгляд, TTS полезна, а когда только раздражает. Говорящая программа с какими функциями пригодилась бы вам?


 0
0 











 Разберем 11 самых важных жизненных вопросов
Разберем 11 самых важных жизненных вопросов






