
Получите новые возможности став разработчиком
Junior, после курса
Middle, с опытом от 1 до 3 лет
Senior, с опытом от 3 лет
Источник: HeadHunter
Нейросети — новая норма, и мы поможем к ней адаптироваться

Курс подойдет каждому



Создали один курс, чтобы вы точно стали разработчиком
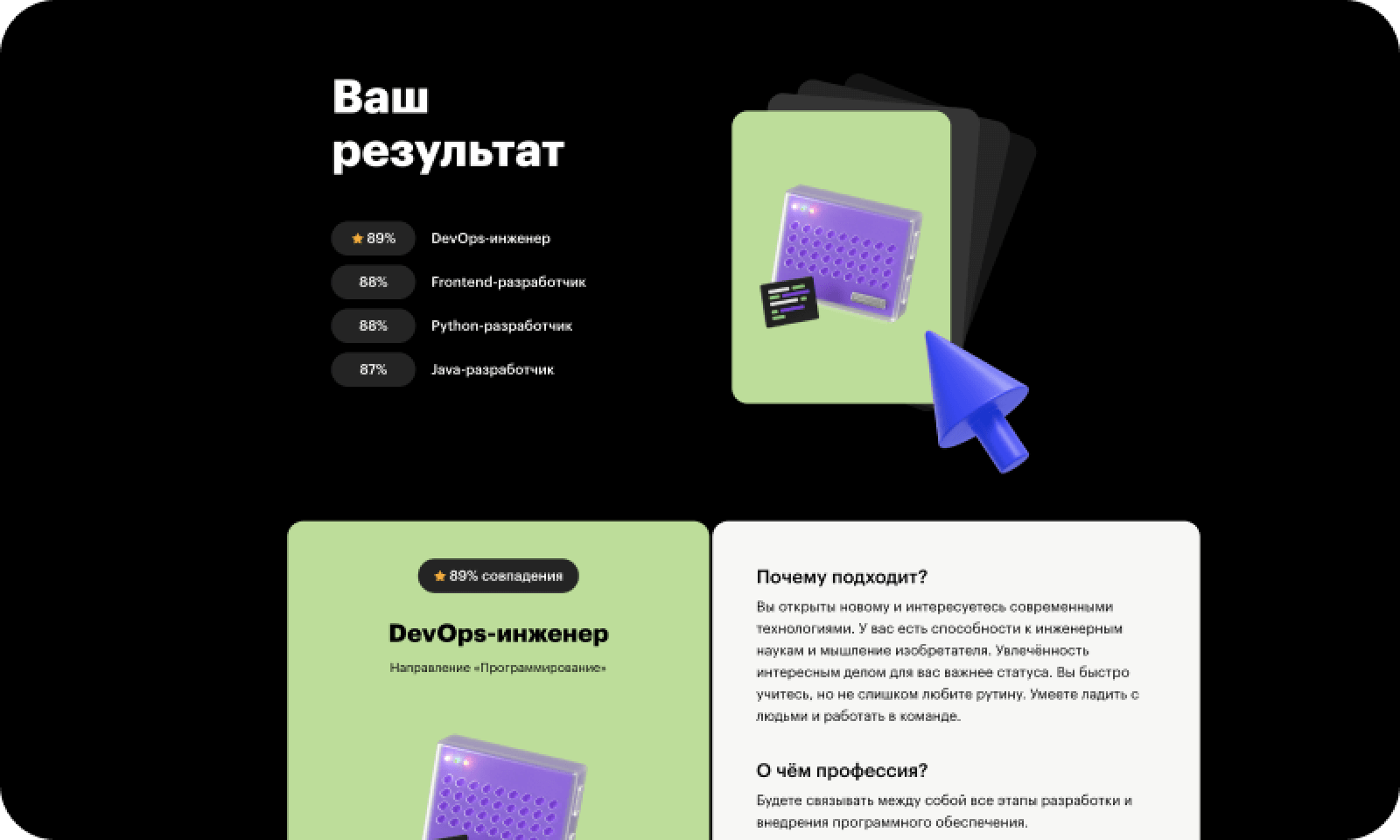
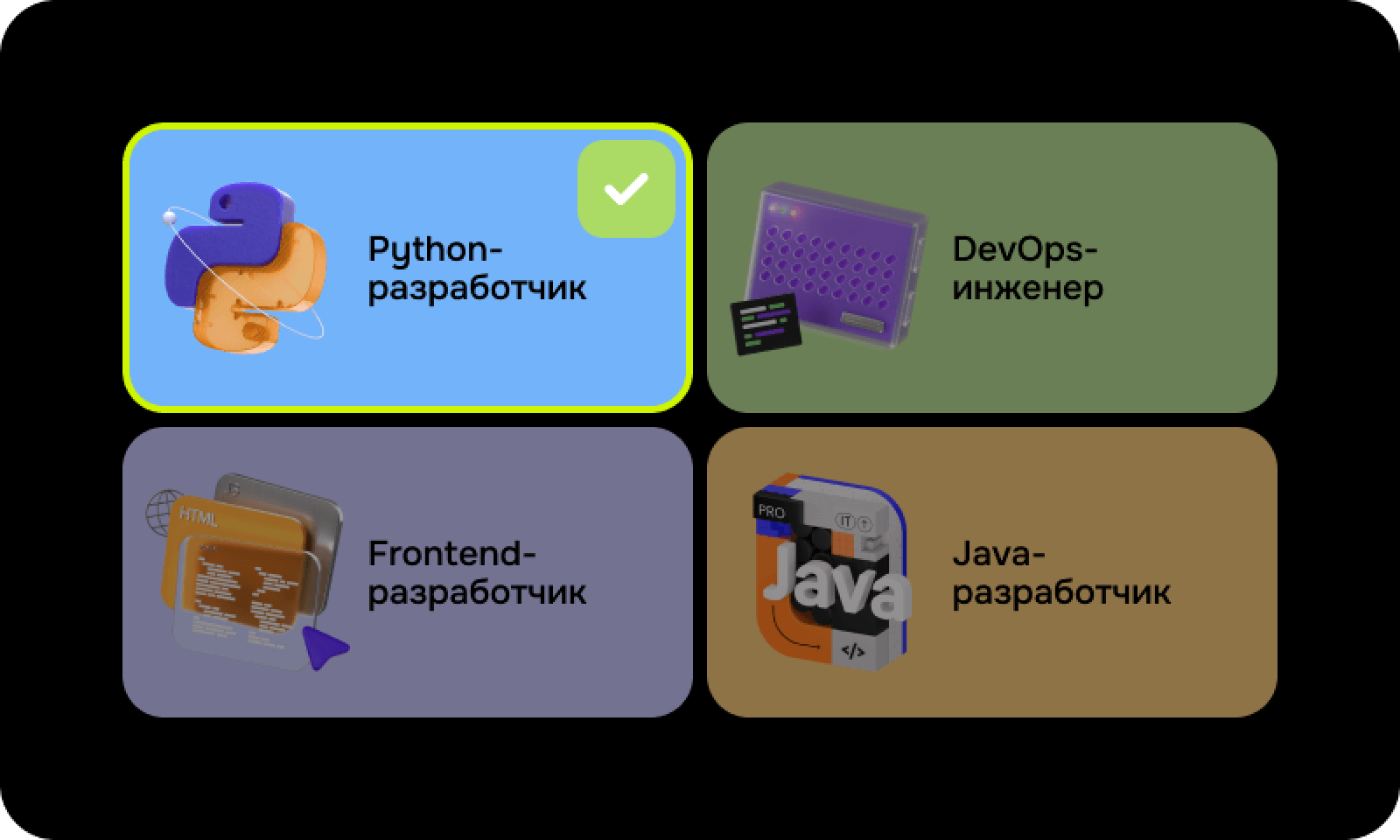
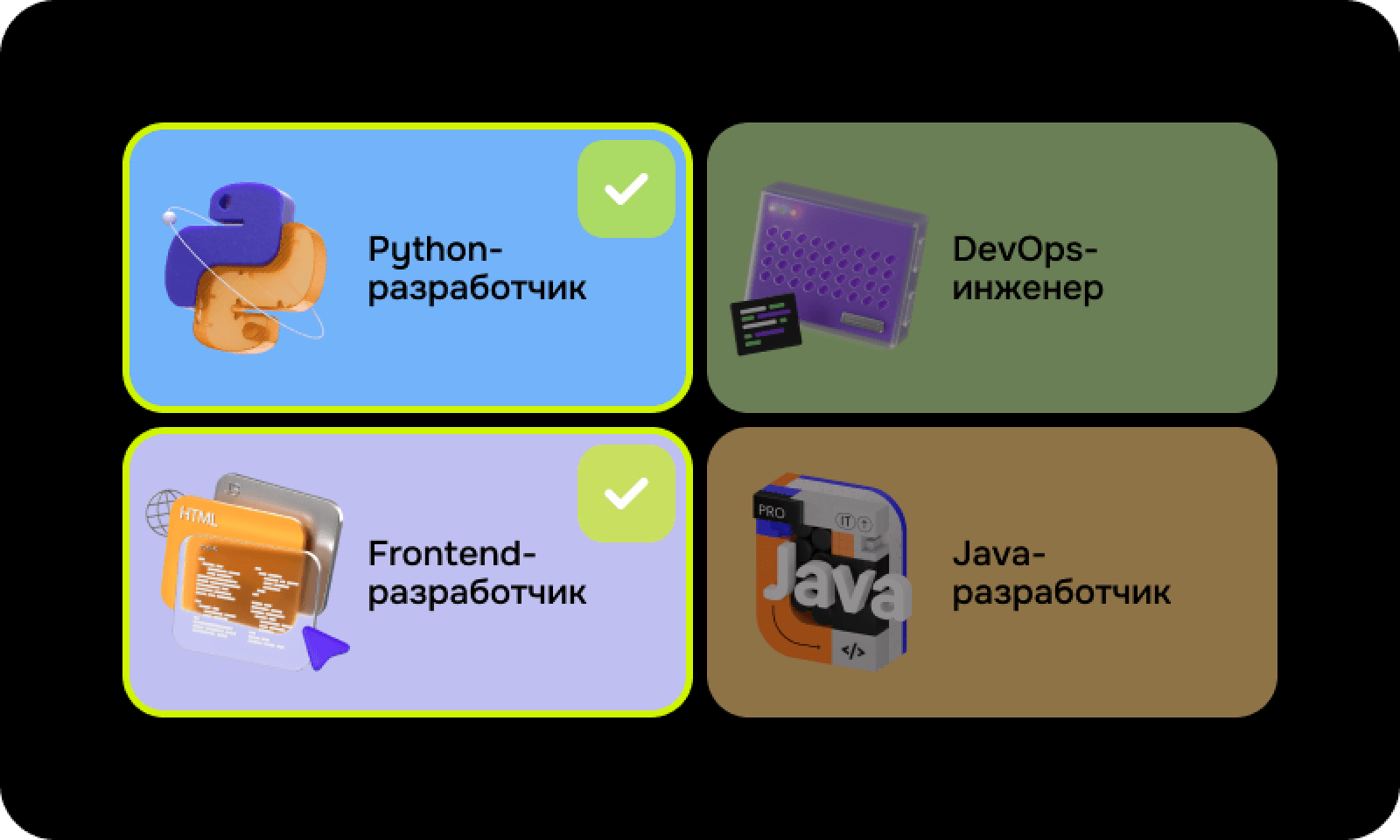
Какие профессии будут доступны на выбор

Средняя зарплата:
218 100 ₽ / мес.

Средняя зарплата:
181 291 ₽ / мес.

Средняя зарплата:
193 166 ₽ / мес.

Средняя зарплата:
218 100 ₽ / мес.

Средняя зарплата:
150 100 ₽ / мес.

Средняя зарплата:
130 100 ₽ / мес.

Средняя зарплата:
200 100 ₽ / мес.

Если поймете, что IT не ваше, сможете выбрать профессии из других направлений
Ваши будущие проекты
Проработаете серверную часть магазина с фильтрами, корзиной, функционалом заказа и оплаты

Разработаете поисковый движок, который будет индексировать страницы сайта и выдавать результаты по формуле

Сможете выбрать для проекта любую тему. Например, написать бота для бронирования отелей с функционалом поиска по локации и стоимости бронирования
Напишите программу для автоматизации работы бизнеса с функционалом управления маркетинговыми активностями, аналитикой по клиентами и рекламе

Разработаете серверную часть и функционал, который есть в любой соцсети: публикация, лайки и комментирование

Развернете удостоверяющий центр для выдачи сертификатов

Разработаете программу, которая будет отслеживать изменения файлов и синхронизировать их с облачным хранилищем

Как проходит обучение

общение и практика

Преподаватели — лидеры IT отрасли

Старший Java-разработчик в СДЭК

DevOps-инженер в Data Travel и Aquiva Labs

TechLead Python в МТС

Frontend-разработчик в Самолете

1С-разработчик в Sonic Soft

Ведущий Frontend-разработчик в Сбере

Senior Frontend-разработчик, ex VK

Руководитель разработки в Газпромбанке

Руководитель IT инфраструктуры в SkyEng

Lead DevOps services в Росгосстрахе

Ведущий Fullstack-разработчик в Data Crunch

DevOps-инженер в ИнфоТеКС

CTO/CIO в Flocktory

Руководитель разработки платформы облачного видеонаблюдения в МТС

Руководитель проектов разработки в Сбере

Frontend-разработчик в Циане

Frontend-разработчик в Газпромбанке

Lead веб-разработки в Газпромбанке

Frontend-разработчик в Газпромбанке

TechLead в Газпромбанке

Frontend-разработчик в Газпромбанке
Мы помогаем с трудоустройством
Программа обучения
- Наш профориентационный тест старается учитывать ваши личные особенности, текущие навыки, прошлый опыт, желания, интересы и другие параметры вашей личности. Поэтому подборка профессий, которые вы получите после прохождения теста, будут вам максимально близки по духу.
- После профтеста вы сможете подробнее узнать про те профессии, которые больше всего вам подходят. Для каждой профессии подготовлен интерактивный рассказ в виде статей с видео, тестами и опытом экспертов. Про каждую профессию вы узнаете: чем занимаются специалисты, сколько можно заработать, где и как искать работу + решите несколько задач, чтобы вы могли «примерить» профессию.
- На выбор доступны основные профессии: Python-разработчик, Frontend-разработчик, Java-разработчик, 1С-разработчик, разработчик игр, менеджер проектов и продакт-менеджер.
- Также на выбор доступны дополнительные профессии из других направлений: аналитика, дизайн, маркетинг, кино, музыка и игры — на тот случай, если помимо IT вам понравится что-то другое.
- Ваши инструменты: Python, PyCharm, GitLab, SQL, MySQL, PostgreSQL, Docker, Flask, FastAPI, HTML, CSS
- Научитесь работать с базовыми алгоритмами и типами данных в Python, понимать принципы ООП, работать с системами очередей задач
- Получите опыт работы с фреймворками Django, Flask и FastAPI, научитесь автоматизации развертывания приложений с Docker и работать с базами данных и API
- Узнаете принципы работы протоколов HTTP, HTTPS и WebSockets, сможете использовать систему контроля версий Git и настраивать CI/CD в GitLab
- Ваши инструменты: Chrome DevTools, CSS, Element Plus, Emmet, Eslint, Figma, GitHub, GitLab, HTML, JavaScript, Jest, Lighthouse, Pinia, Pixel Perfect, React, REST API, Sass, TypeScript, Vite, Vitest, VS Code, Vue 3.0, Webpack
- Научитесь адаптивной верстке на HTML/CSS, разрабатывать интерактивные элементы на JavaScript, работать с промисами, хранилищем данных и Cookie
- Сможете программировать на TypeScript, React.js и Vue.js, работать со сборщиками Webpack, Vite, научитесь командной разработке в Git
- Получите опыт работы с дизайн-макетами в Figma, кросс-браузерной и адаптивной версткой, научитесь оптимизировать страницы, писать тесты на Jest и Vitest
- Ваши инструменты: CSS, Docker, Entity Framework, GitLab, HTML, IntelliJ idea, JUnit, Maven, MongoDB, MySQL, Redis, Spring, Spring Boot
- Научитесь разработке веб-приложений на Java, применять паттерны проектирования приложений, поймете принципы объектно-ориентированного программирования
- Сможете применять алгоритмы для решения разных задач, тестировать приложения, работа с системой контроля версий Git
- Получите опыт разработки многопоточных приложения, научитесь работать с нереляционными базами данных (Redis, MongoDB), получите навыки интеграции с внешними системами (Rest, Kafka)
- Ваши инструменты: 1C:Предприятие 8.3, Конструктор запроса, Конфигуратор, СКД, HTTP, SQL, XML,
- Научитесь работать с оперативным и бухгалтерским учетом, составлять технические задания, управлять совещаниями, дорабатывать типовые конфигурации
- Сможете разрабатывать внешние отчеты, обработки и печатные формы, научитесь разрабатывать подсистемы периодических расчетов, интегрировать 1С с другими системами, работать с SQL и администрированием баз данных
- Ваши инструменты: Unreal Engine, C++, GitLab, Unity, Visual Studio, Blender
- Разработка игр для ПК, Android и iOS, программирование на C++ и визуальный скриптинг на Blueprints, применение принципов ООП и паттернов проектирования в геймдеве, знание идиом C++ и библиотеки STL
- Написание автотестов на C++, создание плагинов для Unreal Engine Editor, работа с resharper для рефакторинга и статического анализа, навыки многопоточной разработки
- Разработка 2D- и 3D-игр на Unity, разработка и адаптация игр под ПК, iOS, Android, создание 3D-моделей в Blender, оптимизация игровых проектов для разных платформ, разработка шейдеров, интеграция SDK и плагинов в Unity 3D-проекты, работа с Git (локальные и удаленные репозитории)
- Ваши инструменты: Google Docs, Google Slides, Google Sheets, Яндекс Метрика, Lean Canvas, Miro, RACI, Customer persona, Excel
- Ведение переговоров с заказчиками, разработка концепции и жизненного цикла проекта, управление командой по Agile и Scrum
- Планирование работы и оценка задач, оценка рисков и стратегическое планирование, формирование команды под проект
- Понимание инструментов продвижения, презентация проектов и результатов
- Ваши инструменты: AppMetrica, Яндекс Метрика, Miro, Tilda, Figma, Power BI, CJM, CustDev, SQL, Excel
- Анализ рынка и конкурентов, проработка монетизации продукта, просчет юнит-экономики, анализ пользователя, управление командой разработки
- Анализ продуктовых метрик, разработка стратегии развития продукта, создание MVP продукта, презентация идей и результатов
- Тестирование гипотез, визуализация и презентация данных
- Если захотите, вместо профессий в разработке можно выбрать профессии из других направлений: маркетинг, дизайн, игры, кино и музыка
- Вас ждет индивидуальная поддержка HR-специалиста. Вместе вы составите резюме, подготовите портфолио и разработаете карьерный план, который поможет найти работу быстрее. Сможете выбрать привлекательные вакансии партнеров и получите приоритет перед другими соискателями.
Вы получите сертификат и подтвердите, что стали разработчиком

вашу квалификацию

Поможем дойти до конца обучения

Подробно разбирает домашние задания, помогает сделать их лучше

Помогает в поиске работы: от плана действий до собеседований

Помогает с вопросами по платформе и прохождению курса
Выгодные условия оплаты
без переплаты и скрытых платежей
Без первого взноса
от цены курса
Воспользуйтесь налоговым вычетом
Часто задаваемые вопросы