
О карьере дата-специалистов: от аналитиков до разработчиков


Мы продолжаем публиковать интересные материалы с совместного митапа GeekBrains и Mediascope. Недавно мы рассказали, как у наших партнёров организована работа с данными. А сегодня они ответят на вопросы студентов.
В качестве дисклеймера эксперты напоминают, что ответы на вопросы — это их частные мнения, отражающие личный опыт. В природе не существует единственно верной методики или однозначного ответа на эти вопросы, поскольку всегда есть множество условий и оговорок, ограничивающих область использования ответа.
— Какие требования предъявляются к начинающим специалистам в сфере дата-аналитики?
Любой специалист, который собирается работать с данными, должен уметь их обрабатывать. Это умение гораздо важней, чем используемые языки программирования и методы. Даже если мы говорим об обработке текстовых файлов shell|bash.
Конечно, преимуществом будет знание SQL или, скажем, Python. Но также важно понимание специфики работы с данными и реальных проблем, с которыми предстоит столкнуться — качество данных, спецификация форматов, типы данных и т. д. Помимо навыков в обработке данных, нужен аналитический склад ума и способность подходить к задаче с правильной стороны — это особенно актуально для дата-сайентистов и аналитиков.
На собеседовании у нас в Mediascope можно столкнуться с разными вопросами. Например, на роль аналитика данных и дата-сайентиста могут попросить описать верхнеуровневый алгоритм для решения следующей задачи: «Как с помощью данных о просмотре телевизора найти людей, у которых есть дети?».
Что же касается инженеров данных, то тут, скорее, будет проверяться глубина знаний заявленных языков программирования. Сами вопросы очень разнообразные — от простых теоретических до действительно сложных и требующих для решения реальный опыт программирования, пускай даже в рамках института. При этом на некоторые вопросы нет единственно верного ответа, а иногда кандидата просят в целом объяснить алгоритм без описания технических деталей реализации.
Сами задания по SQL нет большого смысла прикладывать — они такие же, как в онлайн-тестах в интернете. Хотя у каждого работодателя на собеседовании всегда есть коронная задачка, в которой, по его мнению, кандидат раскрывается полностью. Но таких секретов обычно не выдают.
— На какие вещи нужно обратить особенное внимание при трудоустройстве на начальную позицию в Data Science?
Кандидату очень важно понимать, что потенциальный работодатель подразумевает под этим словом. Иногда под громким названием Data Scientist может скрываться Python-программист, который перекладывает данные из одной базы в другую по вполне простому алгоритму. Или же под DS скрывается вполне конкретная область аналитики, например NLP, AI и ML — это ещё более обтекаемые области, чем big data. Также для многих соискателей становится сюрпризом, что им придётся не только заниматься обучением моделей, но и готовить данные самому.
— Какие технологии нужно знать в первую очередь, чтобы устроиться на работу?
Зависит от многих условий — разброс компаний и решаемых ими задач весьма широк. Из актуального можно выделить:
- Apache Spark — почти повсеместно используется для batch etl обработки данных. Тут акцент хочется сделать не на изучении API как такового, а на понимании общей архитектуры фреймворка — основных базовых блоках;
- Apache Airflow — в качестве управления потоками преобразований;
- SQL — это классика, помимо практической ценности, он сдвигает парадигму мышления, помогает перейти к оперированию наборами данных и декларативному подходу к описанию преобразований.
Как уже отметили выше, важно само умение обрабатывать данные, а не только конечный продукт или технологии. Для каждой роли будет востребован свой продукт. Чтобы узнать, какой именно, достаточно найти на сайте с вакансиями 3–4 описания искомой роли/позиции, в требованиях к которым можно увидеть необходимый технологический стек. Если говорить конкретно о работе с данными, то тут можно встретить всевозможные СУБД и нереляционные базы данных, SQL, Hadoop, OLAP, MPP и многое другое — нужно смотреть конкретно для каждой позиции.
— На каком уровне требуется знание SQL? Вы спрашиваете на собеседовании про Spark/Hadoop?
Для нашей компании SQL важен, так как именно он в основном используется для описания логики трансформаций. Чего-то запредельного мы не спрашиваем, но идеальный кандидат как минимум должен знать и уметь применять:
- типы джойнов, сценарии применения;
- группировки и сортировки;
- оконные функции — хотя бы базовые возможности lag/lead;
- подзапросы (обычные/коррелированные), CTE.
Задача со звёздочкой — понимание, во что все вышеперечисленные конструкции разворачиваются в процессе физического выполнения (необязательно для Spark).
Если в вакансии заявлено знание Spark/Hadoop и опыт работы с ними, то, конечно, тоже спрашиваем, но касаемся базовых понятий и понимания архитектурных концепций — что, зачем и для чего здесь нужно.
— На что обращают внимание, если у начинающего специалиста нет опыта в новой сфере, но он очень-очень хочет начать?
Когда рассматриваем кандидата-джуниора, задаём себе несколько основных вопросов:
- Какой объём знаний/навыков придётся дополнительно вложить в кандидата?
- Насколько быстро он их воспримет?
- Чем его заинтересовать через полгода-год, когда он вырастет из джуна?
Поэтому на этом этапе широта интересов, особенно вокруг выбранной области развития, — это плюс. Структурированное мышление/речь, умение ясно излагать свои мысли, понимание, куда и зачем ты хочешь развиваться — это тоже преимущество. Понятно, что в начале работы трудно предугадать, что именно будет интересовать через год-два, но в любом случае иметь чёткий план развития — ещё один большой плюс.
Широко распространено мнение, что проекты на GitHub сильно повышают шанс трудоустройства. Это верно лишь отчасти. Условно говоря, для Java-бэкендера выложить 101-й клон CRUD на Spring Boot — бесполезно. В типовом на 99% коде разглядеть индивидуальность практически невозможно. Наоборот, взгляд будет цепляться за мелочи, которые, с одной стороны, простительны для джуниор-разработчика, но с другой, вызывают недоумение: «А зачем это тогда показывать?».
В собеседовании новичка на первый план выходят две вещи — это его софт-скилы и то, что он сделал перед тем, как пойти на собеседование. Освежил знания языка программирования или просто почитал что-то на Википедии про большие данные, посмотрел разные требования к позиции и т. д.
— Какие типичные ошибки делают начинающие специалисты (на интервью, на стажировке и т. д.)?
Одна из основных ошибок, которую совершают новички — это отсутствие ответа на вопрос: «Чего ты хочешь от работы/Какие задачи тебе интересны». В 95% случаев ответ: «Я не знаю, никогда этого не пробовал». Нужно понимать, какие цели ты ставишь перед собой в рамках пускай короткого, но конкретного опыта работы. Умение отвечать себе на этот вопрос позволяет экономить много времени, прежде чем «случайно» получится нащупать то, чем интересно заниматься.
Вторая распространённая ошибка — излишняя «скромность» кандидата, который на конкретные вопросы начинает отвечать крайне общими понятиями, боясь удариться об конкретику и показать, что он не понимает. При этом общие ответы воспринимаются куда более отрицательно, чем чёткий ответ мимо.
— В чём особенность сферы обработки больших данных и какая потребность в специалистах? Какого типа люди требуются?
Тут есть пара нюансов в формулировке вопроса. «Особенность» подразумевает сравнение с чем-то. Давайте сравним с привычными для нас вещами — разработкой хранилищ и ETL-пайплайнов на РСУБД классическими ETL-средствами (Informatica, Datastage и т. п.).
В реально «больших данных», которые не умещаются в пределах одного хранилища, переход на новые технологии — это уже не просто дань моде, попытка сэкономить на железе/лицензиях или следствие того, что специалистов на классические технологии уже днём с огнём не сыщешь.
В целом мы выделяем следующее:
- Потоковая обработка данных как норма, появление направления Fast Data.
- Больше кодирования и современных практик разработки по сравнению с пайплайнами на SQL и PL/SQL.
- Больше инструментов, которые надо знать. Раньше было достаточно знания РСУБД (на хорошем/отличном уровне), одного из ETL-инструментов и принципов построения хранилищ/предметной области. Сейчас набор значительно расширен.
- Больше вызовов с точки зрения архитектуры, администрирования. Пространство выбора больше, различных ограничений/нюансов больше.
- Ориентированность на облачные решения. Правда, если говорить о больших данных в реально крупных компаниях, то, скорее всего, организации поднимут частное облако.
— Какие инструменты для анализа данных самые крутые сейчас?
Вопрос очень общий. Нужно понимать, что мы имеем в виду под крутыми и в какой области. На мой взгляд, здесь два понимания, если мы имеем в виду инструменты обработки данных.
Первое — это инструменты, которые позволяют всё более и более непросвещённым в этой области людям работать с данными, дают возможность работать с реально огромными данными вчерашним пользователям Excel. Этот класс инструментов — Self Service Analytics Tools — как раз сейчас зарождается.
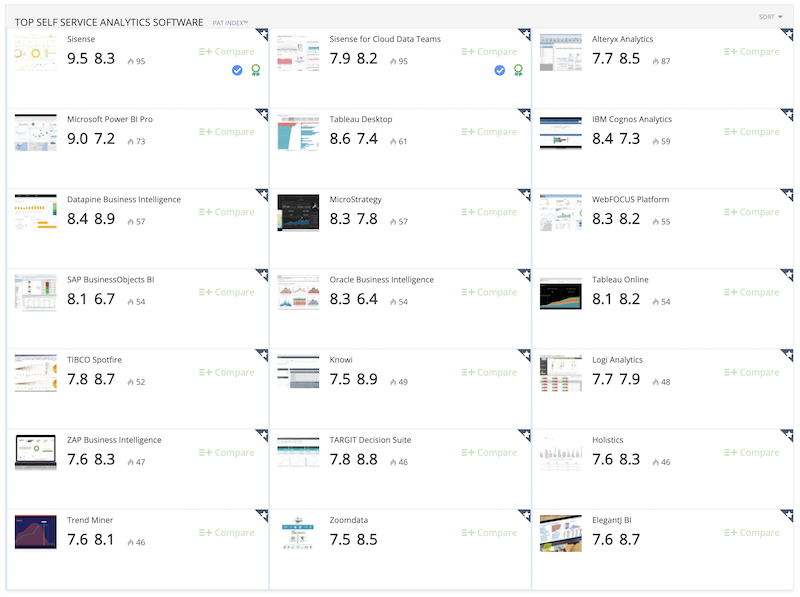
Топовые инструменты в классе по данным predictiveanalyticstoday.com
Второе понимание крутости — это, конечно, скорость вычисления. Тут на первое место встают технологии GPU.
— Каково будущее data science в горизонте 10 лет?
Однозначно не предугадаешь. Да, всё больше компаний начинает принимать решения на основе данных и аналитики, всё больше продуктов используют машинное обучение. Полностью автоматизированные колл-центры — это уже давно не фантастика. Но последние события в мире, всё тот же COVID-19, показал бессилие всех математических моделей в прогнозах.
Другой фактор неопределённости — это «перегретость» области. Многие компании набирают огромный штат дата-сайентистов, но при этом не могут начать экономить и зарабатывать деньги на этом. Конечно, data science через 10 лет будет очень востребован, но, возможно, мегахайп уйдёт уже через 3–5 лет.
— Какое влияние окажет интернет вещей на использование больших данных? Как будут развиваться хранилища и обеспечиваться их безопасность?
Интернет вещей уже стал менять обычное представление об аналитических системах, потому как открыл целый ряд возможностей, связанных с real-time-аналитикой и принятием молниеносных решений. Их уже нельзя реализовать на старых аналитических технологиях и архитектурах.
Дальнейшее проникновение интернета вещей в нашу ежедневную жизнь будет сильно её менять и, будем надеяться, в лучшую сторону. Сами технологии уже позволяют делать вещи, кажущиеся почти фантастическими обычному обывателю.
— Есть ли сейчас «свободные» большие данные, или они все принадлежат большим компаниям?
Существует огромное количество источников таких данных, и большие компании достаточно лояльно дают к ним весь возможный доступ. За небольшие деньги можно купить, например, данные обо всех перелётах или перемещении морских судов. При этом заплатить придётся не за сам доступ, а за удобный интерфейс выгрузки этих данных. Даже государства такие данные публикуют, тот же сайт Открытого Правительства РФ даёт много статистик и детальных данных.
— В каких областях используются больше нейронные сети, а в каких — классические модели машинного обучения?
Тут всё как в учебнике, не получится добавить ничего интересного. Нейронка хорошо работает, если нужно найти неочевидные связи между событиями, классические модели лучше работают с понятным набором атрибутов для обучения.
— Какие лучше выбрать софт и железо для обработки больших данных?
Лучше всего выбирать осознанно, исходя из потребностей конкретного проекта с учётом перспектив развития. Делать пилоты, proof of concept, эмулировать типичную нагрузку.
Конкретный ответ всегда зависит от многих факторов, часть из которых даже не технического характера. Например, бюджет, наличие в компании определённых специалистов, необходимость поддержки, характера данных, прогнозируемого характера нагрузки и т. д. В целом, сейчас наблюдается тенденция ухода в облачную инфраструктуру с различной степенью погружения.
Также относительно модным сейчас становится отказ от традиционной Hadoop-платформы (HDFS + YARN) для ETL-трансформаций в сторону Spark on k8s + S3.
Конкретный выбор зависит от особенностей проекта.
В любом случае, при выборе нод под нагрузку следует в первую очередь обращать внимание на сбалансированность показателей CPU/RAM/Disk. Точные цифры опять же варьируются от проекта к проекту.
— Какие продукты/инструменты лучше всего подходят для ETL-обработки данных в big data при продуктивном использовании в компании?
По ряду причин подходы и инструменты, используемые в классическом ETL (Informatica, DataStage и др.), плохо прижились в мире big data. Части задач, которые они решали при классическом подходе, здесь либо не существует, либо у них отдельные инструменты для решения. Например, для оркестрации потоков данных используется Oozie, Airflow, Luigi и др.
Кроме того, мы видим явный и осознанный уход в парадигму «всё есть текст». Точнее, ещё более радикально — «всё есть код». Это позволяет решить множество проблем с версионированием, code review, операционными задачами. Старые инструменты здесь вписываются крайне плохо. Попытка закодировать все трансформации и пайплайны вручную требует на первом этапе очень квалифицированную команду, которая сможет выработать подходы, построить жёсткий фреймворк для дальнейшей разработки, чтобы это всё не скатилось через некоторое время в болото.
По этим причинам сейчас наблюдается тенденция к использованию codeless-средств построения ETL, которые упрощают разработку и конфигурируются через код. Или умеют генерировать код в какой-либо из популярных фреймворков, обычно Spark. По такому же пути идут и большие игроки — Azure Data Factory, например.
В качестве стандартной (точнее, очень часто используемой) открытой связки для ETL мы бы рассматривали Spark + Airflow + NiFi (тут с оговорками) + Kafka (как общая шина данных) + что-то для потоковой обработки (Spark Streaming или Flink). В любом случае над ней придётся попотеть, но зато меньше вероятности встретить сильно протекающие абстракции.
Это не единственный материал, который мы подготовили совместно с экспертами Mediascope. В более раннем посте вы, например, сможете подробно узнать, как устроена дата-платформа компании.
Освоить востребованную профессию в Data Science можно всего за полтора года на курсах GeekBrains. После учёбы вы сможете работать по специальностям Data Scientist, Data Analyst, Machine Learning, Engineer Computer Vision-специалист или NLP-специалист.
Освоить востребованную профессию в Аналитике больших данных можно всего за полтора года на курсах GeekBrains.