
Как работают оптимизаторы SQL-запросов в Mediascope


В конце декабря прошёл совместный митап GeekBrains и Mediascope — лидера российского рынка медиаисследований, мониторинга рекламы и СМИ, компанией, постоянно обрабатывающей огромные объёмы информации. Мы уже писали, как в Mediascope устроена инфраструктура работы с данными, а в отдельном посте эксперты компании ответили на множество вопросов по развитию в data science. В заключительном материале по митапу тимлид команды системной разработки в направлении больших данных Mediascope Александр Капустин расскажет об оптимизаторах и их использовании с Apache Spark.
Когда у кого-то запрос обрабатывается несколько часов, а ты приходишь, меняешь пару строчек, и получаешь результат через минуту или две — это приятно. Лёгким движением руки ты можешь добиться значимых усовершенствований. Но прежде чем заняться непосредственно оптимизацией, нужно ответить на два важных вопроса.
Цель оптимизации. Допустим, сейчас запрос обрабатывается час. А какое время нас устроит? Без видения финального результата оптимизация бессмысленна. Вероятно, мы потратим много сил впустую, хотя этого от нас не требовалось. Иногда изменение бизнес-постановки может дать больше, чем мучения с физической оптимизацией.
План выполнения запроса. В нашем случае декларативное описание того, что мы хотим получить на выходе, нужно преобразовать в императивное указание Spark, что должно быть выполнено. Каждый запрос проходит несколько стадий:
- Построение AST-дерева на основании запроса — parsed logical plan. Разбирается запрос на основании синтаксиса SQL и преобразуется в дерево разбора.
- Привязка к метаданным (таблицы, столбцы) — analyzed logical plan. На основании дерева разбора определяются метаданные сущностей, которые используются в запросе, проверяется, что все ссылки в запросе идут к существующим данным.
- Оптимизация плана запроса — Optimized Logical Plan. Обычно оптимизируется либо полное время выполнения запроса (OLAP), либо процесс получения первых данных (OLTP) с учётом доступных ресурсов.
- Физический план выполнения — Physical Plan. Строится императивный процесс получения результата с учётом доступных ресурсов и распределённого характера данных.
Все примеры, на которых мы разберём тему дальше, будем проводить по трём таблицам. У нас есть клиент, есть несколько банковских счетов, которые к нему привязаны. У счетов есть остаток, который считается за каждую дату, даже если он нулевой. От них нам нужны ID и некоторые поля.
Далее для примера возьмём упрощённую связку из трёх таблиц.
- Клиент.
- Банковский счёт. У одного клиента может быть несколько счетов.
- Остаток на счёте. Остаток считается за каждую дату, даже если он нулевой.
В работе с оптимизаторами мы будем использовать Spark 3 (3.0.1), данные сохраним в Parquet, как наиболее полно поддерживаемом с точки зрения набора оптимизаций формате. Таблица остатков — наибольшая, и она будет партицирована по дате:
import org.apache.spark.sql.types._
val customerSchema = StructType(Array(
StructField("customer_id", LongType, false),
StructField("name", StringType, true)))
val accountSchema = StructType(Array(
StructField("account_id", LongType, false),
StructField("customer_id", LongType, false),
StructField("account_number", StringType, true)))
val balanceSchema = StructType(Array(
StructField("on_date", DateType, false),
StructField("account_id", LongType, false),
StructField("balance_rub", DataTypes.createDecimalType(), false)))
Это оптимизатор, основанный на применении к дереву запроса набора предопределённых правил, которые его трансформируют. В Spark Catalyst наработана большая база (порядка сотни) подобных правил . Здесь они применяются независимо от характера входных данных и не учитывают распределение последних.
Главное преимущество данного оптимизатора — в простоте. Он хорошо подходит, если надо вытащить небольшое количество данных. Однако этот оптимизатор не учитывает характер распределения данных и не знает, сколько записей в таблицах. Поэтому на сложных запросах он начинает ошибаться. Хотя при OLTP-запросах обычно сам примерно знаешь, что должно получиться, и можешь написать запрос руками.
Типичный пример оптимизации — filter pushdown, фильтрация данных до вычитывания в память:
spark.sql("select * from customers where customer_id = 1").explain(true)
+- FileScan parquet [customer_id#0L,name#1] Batched: true, DataFilters: [isnotnull(customer_id#0L), (customer_id#0L = 1)]
PushedFilters: [IsNotNull(customer_id), EqualTo(customer_id,1)]
spark.sql("select * from customers where string(customer_id) = '1'").explain(true)
+- FileScan parquet [customer_id#0L,name#1] Batched: true, DataFilters: [isnotnull(customer_id#0L), (cast(customer_id#0L as string) = 1)]
PushedFilters: [IsNotNull(customer_id)]
Spark может пойти таким путём: вычислить все Parquet-файлы, которые относятся к таблице customers, и проверить их на id=1. Но это будет неоптимально, потому что нам надо вытащить всю таблицу, чтобы получить данные только от одного клиента.
Хоть у нас здесь нет индексов, мы можем выяснить, на каких страницах есть строки, где значение равно единице. Оптимизатор для PushedFilters указывает (IsNotNull (customer_id) и что поле равно единице. Соответственно, нам в память будут вычитаны те строчки, которые необходимы. Это намного меньший объём данных, а запрос обработается быстрее.
В нашем случае оптимизатор легко запутать, и он не сможет обработать запрос. Например, если мы преобразуем поле customer_id в строку. Оператор видит, что мы над полем производим какую-то функцию и реагирует: всё, я не смогу теперь на уровне файлов определить, что ты хочешь. Придётся вычитывать все данные в память и там фильтровать.
Поэтому когда пишут запрос данных, надо обращать внимание на типы данных и стараться в фильтрациях и джойнах не использовать функции, которые что-то делают с полями фильтрации или с полями джойна. Лучше преобразовать всё это заранее и на уровне константы.
Ещё одна типичная оптимизация — constant propagation.
spark.sql("select a.* from accounts a join customers c on a.customer_id = c.customer_id where c.customer_id = 1").explain(true)
+- FileScan parquet [account_id#4L,customer_id#5L,account_number#6] Batched: true, DataFilters: [(customer_id#5L = 1), isnotnull(customer_id#5L)]
PushedFilters: [EqualTo(customer_id,1), IsNotNull(customer_id)]
+- FileScan parquet [customer_id#0L] Batched: true, DataFilters: [isnotnull(customer_id#0L), (customer_id#0L = 1)]
PushedFilters: [IsNotNull(customer_id), EqualTo(customer_id,1)]
Берём простейший запрос inner join из двух таблиц по полю customer ID и задаём, что нам нужен customer ID = 1 только по таблице customers. Но оптимизатор умный и видит, что в таблице accounts нам тоже нужны не все customer, а только равные единице. Поэтому сначала он может сделать ограничения. И мы видим, что для обоих таблиц у нас есть соответствующая фильтрация. То есть оптимизатор сам уменьшает количество данных, которые утягиваются в память.
Cost Based Optimizer
Это более продвинутый оптимизатор, который действует исходя из того, какие данные есть в таблицах, насколько равномерно они распределены. Он уже может делать более продвинутые вещи.
Например, если оптимизатор понимает, что ему, чтобы получить результат, надо обойти более 30% записей, он предпочтёт прочитать таблицу полностью. В этом случае ему надо будет пройтись только по data page. Если идти по пути index scan, то сначала необходимо сходить в index page, затем в data page. И получится медленнее, чем просто прочитать таблицу целиком.
Также он понимает больше в распределении данных. Например, у нас есть таблица customers. Допустим, чуть ли не 50% технических счетов принадлежат некоему банку. И когда мы говорим системе отобрать все счета, где customer id=1, оптимизатор понимает, что это не типичный клиент с двумя-тремя счетами. Это клиент, для которого придётся вытащить полтаблицы. А потому опять разумнее сделать table scan.
Кстати, здесь как раз не работает правило, когда советуют не подставлять явное значение констант в запрос. В большинстве случаев это безопасно и даёт скомпилированный готовый план запроса. Но оптимизатор начинает промахиваться. Он ожидает, что ему надо достать три записи, а мы ему на входе подставляем параметр, для которого их пятьдесят. Поэтому для подобных вещей обычно склеивают и компилируют чуть ли не весь запрос целиком.
Ещё этот оптимизатор пытается преобразовать порядок соединения таблиц. В зависимости от типа джойна и размера таблиц бывает важно определить, какая таблица ведущая, а какая второстепенная. И он может это сделать. Но ему нужна актуальная информация. Если данные устарели, то результат будет не лучшим.
Как оптимизаторы работают с Apache Spark
В реляционной базе данных у нас просто таблицы, которые лежат в одном месте. В Apache Spark у нас много разрозненных источников информации, всё распределено по разным узлам. Собирать и считать статистику становится сложно.
В Spark есть несколько экзекьюторов, которые также разбросаны по узлам. Здесь нет индексов, по крайней мере для Parquet-файлов. То есть в итоге мы можем сказать, что какого-то значения на странице нет, но не можем сказать, где лежит конкретная запись. Поэтому все правила в основном относятся к Rule Based Optimizer. Когда я в последний раз смотрел на исходный код Spark, Cost Based Optimizer был там в экспериментальном состоянии. В последние версии его как штатный не включили.
В принципе по истории развития Spark виден путь к оптимизации. Изначально оптимизаторы вообще не предполагались, всё руками выписывалось. Ситуация изменилась, когда перешли на data frame и data set. Дальше уже появился оптимизатор Catalyst.
По факту все оптимизации преследуют две задачи — прочитать меньше и оптимально соединить две таблицы в условиях джойна. Поскольку у нас основная борьба ведётся за то, чтобы читать не все данные, а только часть, то важна правильная политика партицирования. Мы фильтруем, например, по дате. Если у нас данные секционированы по дате, то оптимизатор понимает, что ему не нужно читать все каталоги, а достаточно только одной партиции, к которой надо применить фильтрацию. Это позволяет уменьшить объём вычитываемых данных.
Поговорим о присоединении таблиц: представим, что у нас их две. Их нужно подсоединить по ключу. Есть три варианта.
Nested loop join
Самый простой: мы бежим по одной таблице и, если есть индекс, ищем по нему значения во второй. Или каждый раз задействуем table scan. Этот вариант хорошо подходит для OLTP-запросов и случаев, когда все поля проиндексированы. Но если речь о big data, тут будут проблемы.
algorithm nested_loop_join is for each tuple r in R do for each tuple s in S do <------ Тут должен быть index seek (а если нет, то всё плохо) if r and s satisfy the join condition then yield tuple <r,s>
Hash join
Выбираем две таблицы и смотрим, какая меньше. Из полей, которые подходят под условия присоединения, строится hash-таблица. Ключом будет хеш значений, вычисленный из полей, на основе которых мы проводим соединение. А по большой таблице мы просто бежим сканом. Если всё влезает в память — хорошо. Если нет, разбиваем на части, вычисляем для каждой строчки хеш по полю джойна и смотрим, есть такое значение или нет.
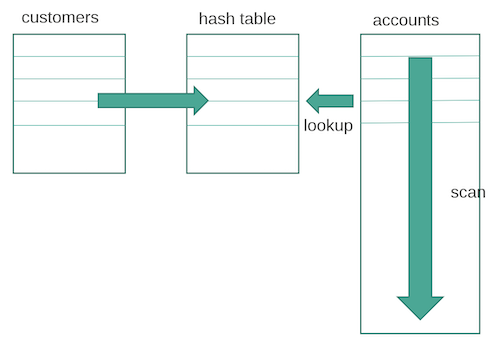
Sort merge join
Требуется, чтобы обе таблицы были отсортированы по ключу, по которому они джойнятся. Это может быть физическая фильтрация или сортировка по индексу. Далее просто находим ключ в одной таблице и отбираем записи по нему во второй. И так ключ за ключом. Этот способ менее требователен к объёму памяти, чем предыдущий.
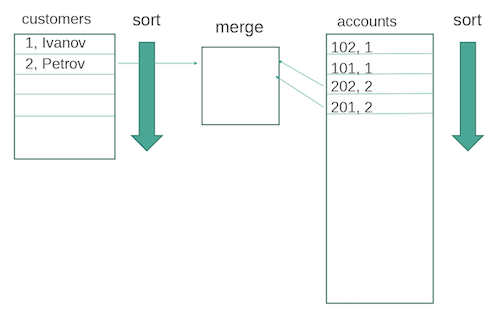
Shuffle hash join
Усложняем задачу. Данных становится больше, они лежат на разных узлах. И экзекьюторы Spark запущены на разных узлах. Вариант здесь — shuffle hash join. То есть для каждой таблицы строится хеш по ключу джойна, дальше мы перебрасываем информацию так, чтобы на каждом узле были одни и те же данные. А затем происходит классическое присоединение hash join. Правда, всё равно можно словить out of memory, если данные разбились на недостаточное количество кусков.
Если одна из таблиц маленькая, можно обойтись broadcast hash join. Куски большой таблицы лежат на разных узлах, и на каждый мы множим маленькую таблицу. Далее вновь происходит классический hash join.
И да здравствует open source! Можно залезть в исходный код Spark и посмотреть полный список всех оптимизаций, который Rule Based Optimizer может применять, и узнать, как выбирается стратегия джойна. Вся прелесть в том, что ты видишь всё, и это восхитительно.
Освоить востребованную профессию в Data Science можно всего за полтора года на курсах GeekBrains. После учёбы вы сможете работать по специальностям Data Scientist, Data Analyst, Machine Learning, Engineer Computer Vision-специалист или NLP-специалист.
Освоить востребованную профессию в Аналитике больших данных можно всего за полтора года на курсах GeekBrains.