
Как организована работа с данными в Mediascope


В конце декабря мы в GeekBrains провели совместный с Mediascope митап. Mediascope — лидер российского рынка медиаисследований, мониторинга рекламы и СМИ. Это компания, которая обрабатывает огромный объём информации. В своём выступлении директор по работе с большими данными Василий Кузьмин рассказал, как сейчас в Mediascope организована эта работа. Текстовая версия выступления — в этой статье.
Концепция
Когда я пришёл в Mediascope, перед нами стояла задача разработать платформу для обработки данных, которая будет соответствовать более высоким требованиям по сравнению со старыми системами.
Mediascope собирает данные из разных источников: их десятки, они разнородные по объему и качеству информации. Из одного идут миллионы записей в день, из другого данные поступают раз в полгода. Данные приходят как из источников внутри компании, так и с устройств, которые Mediascope раздаёт респондентам. А ещё их предоставляют партнёры — крупные рекламные и интернет-холдинги, медиа. Они зачастую являются и потребителями нашей аналитики, и поставщиками сырых данных.
Старое решение было построено по тоннельному принципу: для каждого источника создавался отдельный канал со своими системами. Новая платформа должна была решить две задачи:
- Сделать доступной кросс-медийную аналитику. Это одна из самых актуальных и в тоже время сложных задач на медиарынке сегодня. Чтобы, например, посчитать, сколько раз человек видел ту или иную рекламу по телевизору, в своём телефоне или компьютере, нужно не только получить информацию из разных источников, но и далее собрать все это в единое целое.
- Работать с большим объёмом данных. На медиарынке количество информации выросло, по одним оценкам, на порядок, а по другим — на два. И объём данных не просто увеличился, он продолжает постоянно расти.
Мы спроектировали новую платформу в классической манере — использовали не только мой опыт, но вообще все лучшие подходы, которые есть на рынке. Не то чтобы это были революционные решения — напротив, всё опробованное и достаточно консервативное. Я бы охарактеризовал это как «топ минус один». Большие данные — сравнительно молодая отрасль. Топовые подходы ещё слишком свежи, а потому ненадежны. Мы же должны были построить платформу со сверхвысокой надежностью. Поэтому использовали проверенное поколение технологий, которые тем не менее в топе.
Мы сделали масштабируемую платформу и собрали единую точку входа. Общая концепция устроена так же, как и в 70% успешных проектов. В её основе — канонический подход со стороны архитектуры. Если вы посмотрите, как это реализовано в крупных компаниях, с большой долей вероятности это будет нечто похожее. Во-первых, потому что одни и те же архитекторы курсируют из компании в компанию. Во-вторых, потому что это правда работает.
Поэтому наша концепция достаточно универсальна.
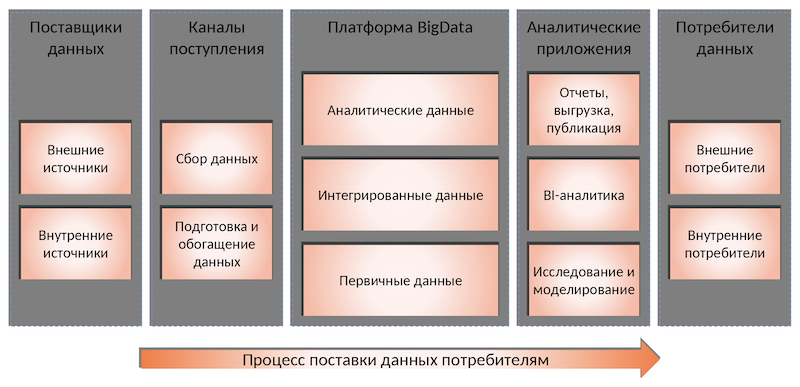
Поставщики данных
Всегда есть поставщики данных — наши собственные источники и сторонние. Собственные данные мы можем более тщательнее проверить, если видим, что данные некачественные. А информацию из внешних источников мы принимаем как есть. Именно поэтому важно уметь работать с данными разного качества.
Каналы поступления данных
Мы используем Apache NiFi — оркестровщик потоков данных, который отвечает за то, чтобы каждую систему в нужный момент дёрнуть, получить от неё данные и положить на вход в нашу платформу. В качестве транспорта между NiFi и платформой используется Kafka.
Платформа Big Data
Сама платформа — это кластер Hadoop. Сейчас там около 50 дата-узлов, но и его уже надо расширять. Сейчас мы с этим кластером переехали в облако — используем, кстати, SberCloud. Здесь есть несколько слоёв. Они каноничны с точки зрения не только Hadoop, но и классического подхода к данным.
- Первичные данные — это информация как есть, но уже приведённая к нашему формату. Мы используем формат файлов Parquet.
- Интегрированные данные — это точка, где мы всю информацию привели к единому виду, пометили нашими идентификаторами и связали между собой. С этого момента от данных из одной системы можно перейти к данным из другой.
- Аналитические данные — это результаты расчётов, витрина данных, которые содержат какие-либо деривативы или производные — их по-разному называют. Важно, что речь идёт не обязательно об агрегатах, это могут быть и детальные записи.
К первичным данным есть доступ только у программистов, дата-инженеров. Это технический уровень, который мы не показываем даже внутренним пользователям. К двум другим уровням имеют доступ наши клиенты, хоть и с ограничениями. Но важно, что наш API начинается со слоя интегрированных данных. Мы изначально строили структуру так, чтобы эти уровни не стыдно было кому-то показать.
Аналитические приложения
Это программы, сервисы и службы, которые используют данные и что-то с ними делают. Условно их можно разделить их на три основные группы:
- Отчёты, выгрузка, публикация.
- BI-аналитика. Здесь мы используем ClickHouse как аналитическую базу данных. Там выполняются быстрые запросы, туда копируются витрины, чтобы быстро отдавать данные.
- Исследование и моделирование. Это точка, через которую данные смотрят дата-сайентисты. У нас есть внутренние и внешние специалисты. Последние — сотрудники наших клиентов, которые могут дополнительно подгружать свою информацию.
Потребители данных
Это приложения, которые непосредственно платформу не видят, но смотрят на неё через призму аналитических приложений.
Архитектура
Если смотреть на платформу с точки зрения архитектуры, она выглядит примерно так. Это картинка годичной давности. То, что есть сейчас, на слайд уже не уместится. Так реализована концепция, которую я описал.
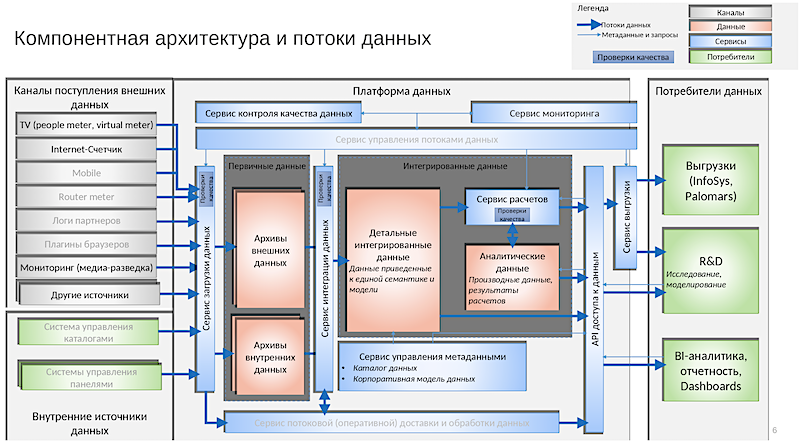
Из примечательного здесь:
- Система управления каталогами. Её мы внедрили отдельно.
- Системы управления панелями. Панели — это для нас клиенты, респонденты.
- Первичные данные, где есть архивы внешних и внутренних данных. Правда, мы используем термин Persistent Staging Area вместо архивов.
- Интегрированные данные — внутри выделены подразделы.
Сервисы
А вот схема сервисов:
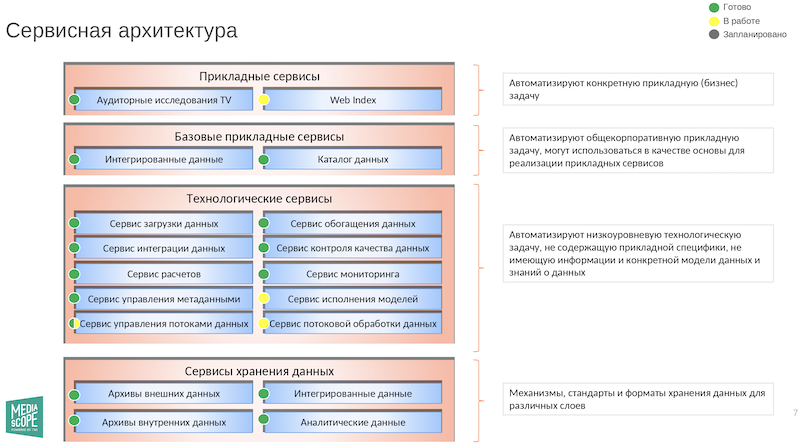
Из интересных сервисов:
- Сервис обогащения данных — это инструмент, который позволяет на основе правил автоматически достраивать их.
- Сервис контроля качества данных — по понятным причинам это просто священная корова. В этой сфере есть промышленные решения, есть самопальные. Вечная тема для дискуссий, что здесь лучше использовать.
- Сервисы мониторинга. Надо постоянно знать, что происходит в цепочках, корректно ли всё работает.
- Сервисы исполнения моделей. Дата-сайентисты пишут модели на Python. Если грубо говорить, они получают данные на входе, а на выходе дают ответы. Нужно, чтобы эти разработки встраивались в процесс как картридж — при необходимости их можно вставить, извлечь или внутри что-то поменять. А ещё эти модели не должны обрушивать весь процесс, если дата-сайентист чего-то не учёл. Так что этот сервис крайне важен.
- Сервис потоковой обработки данных. Почти все данные у нас сейчас идут пакетами. Но есть источники, которые умеют отдавать информацию в потоковом режиме. Поэтому какую-то часть расчётов мы переводим на стриминговую обработку. И даже ведём переговоры, чтобы отдавать некоторым потребителям стриминговую аналитику. Это называется near real-time аналитика, то есть не в реальном времени, но почти.
- Сервис управления потоками данных — оркестровка потоков данных.
Инструменты работы с данными платформы
Мы реализовали три варианта подключения к данным. Первый — через Spark. Это для продвинутых пользователей, которые знакомы с Zeppelin или Jupyter. Можно также подключиться к большому хранилищу данных — например, тот же Tableau может построить дашборд. Наконец, можно работать непосредственно с Hadoop как с файлами — это самый низкоуровневый доступ.
- Zeppelin и Jupyter. Zeppelin здесь, потому что мы используем Spark как среду преобразования данных. В целом тенденция на рынке именно такая: где есть Spark, там будет Zeppelin. Если в работе используется много Python, то будет Jupyter. Но вообще это две конкурирующие оболочки, так что подходят оба варианта.
- Datagram. Его используют для работы SQL-щики и дата-инженеры. Они описывают запросы, цепочки преобразования данных, это всё становится кодом, и в runtime-процессе у нас работает Scala. В качестве альтернативы мы могли бы нанять больше разработчиков Scala, чтобы они тот же код написали сразу. Но мы работаем с Datagram.
- Confluence. Мы тщательно ведём документацию и описываем каждый шаг, не ленимся.
- Enterprise Architect. Используем для высокоуровневой архитектуры. Вся модель данных изначально ведётся там.
- Tableau, PowerBI (от последнего почти совсем отказались).
Требования к дата-специалистам
У проджект-менеджеров есть PMBoK — документ, в котором содержатся стандартизированные требования к управлению проектами. Для дата-специалистов тоже есть подобное издание под названием DAMA. Там, помимо прочего, содержится набор ролей, которые бывают при работе с данными.
- Дата-офицер — это общее название для дата-специалистов.
- Дата-инженер — разработчик. И к нему предъявляются те же требования, что и к разработчикам.
- Дата-сайентист — решает нетривиальные задачи, часто используя сложные математические алгоритмы, и на выходе выдаёт обычно какой-либо алгоритм.
- Дата-аналитик — специалист, к которому предъявляются самые высокие требования. Он должен разбираться во всём, знать структуру данных и хорошо в ней ориентироваться, понимать, когда данные обновляются, какое у них качество. Если у кого-то появляются вопросы, то идут к нему.
- Дата-архитектор — отвечает за структуру и то, как будут лежать данные.
- Дата-оунер — это не специальность, а роль. Он отвечает за систему источников. Дата-оунер обычно относится не к IT, а к бизнес-подразделению.
- Дата-стюард — специалист, который обычно может вносить исправления в данные, вручную поправлять ошибки, проверять данные. К ним обычно предъявляются минимальные требования.
- Специалист по безопасности — понятная роль. Человек, который занимает подобную должность, должен хорошо разбираться во всём, как и дата-аналитик.
От начинающих специалистов обычно требуют как минимум знания SQL. Это будет первый вопрос на собеседовании. Я ещё обычно смотрю на университет, потому что качество образования везде разное. Также имеет значение, есть ли в резюме дополнительные курсы, готов ли человек вкладываться в образование временем и деньгами. Понятно, что от начинающего сразу много требовать не будут, ему дадут время на обучение. Так что будьте готовы учиться и читать документацию, это очень важно.
Освоить востребованную профессию в Data Science можно всего за полтора года на курсах GeekBrains. После учёбы вы сможете работать по специальностям Data Scientist, Data Analyst, Machine Learning, Engineer Computer Vision-специалист или NLP-специалист.
Освоить востребованную профессию в Аналитике больших данных можно всего за полтора года на курсах GeekBrains.